 中國
中國 Global
Global

擁有18年曆史的谷歌正在利用人工智慧和機器學習技術給自己的產品進行一次「翻新」和「升級」。
11月17日,這家科技巨頭宣佈,基於上述技術開發的神經網路機器翻譯系統(GNMT:谷歌 Neural Machine Translation),正式被應用到谷歌翻譯中。
拋開這個有些晦澀的技術名稱,簡單來說,它在兩方面給谷歌翻譯帶來了巨大改變。首先,翻譯單位由「單詞」、「短語」變成了「句子」,能夠對整句進行充分理解和翻譯;其次,在整句翻譯之後,還能夠在更廣泛的語境中進行調整,找出最相關的語言和詞彙,來進行再次調整和安排,最終讓翻譯出的語言更自然順暢。
谷歌翻譯產品經理Barak Turovsky在視訊採訪中告訴我們,新的機器翻譯錯誤率減少了55%—85%。目前,35%的線上翻譯需求,已經可以使用神經網路機器翻譯。
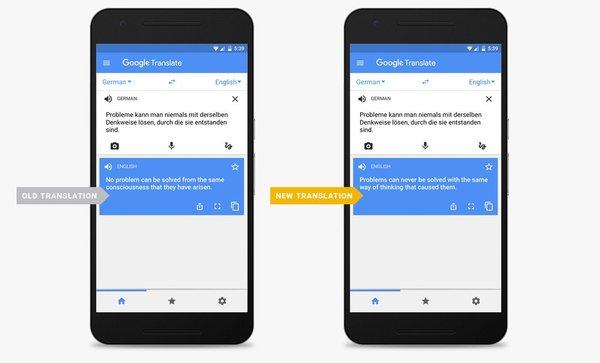
作為谷歌旗下最成功的產品之一,每月有超過5億人使用谷歌翻譯。每天要完成10億次翻譯,涉及的單詞量超過1400億個。龐大的使用者量和翻譯需求量,使得每一次微小的技術改進都會產生巨大的影響。
「神經網路機器翻譯系統是一個重要里程碑,此次更新對谷歌翻譯的改進遠超過去十年。」谷歌在新聞稿中對於這次技術提升給予了極高評價。今年4月,谷歌剛剛慶祝了谷歌翻譯上線十週年。而這次的重大技術更新,也成了工程師們給這款產品最好的一份禮物。
與以往翻譯技術的改進不同,這次神經網路機器翻譯系統能夠像人類一樣,擁有自我學習的能力。
根據Barak Turovsky的介紹,機器學習和訓練首先需要大量樣本,谷歌翻譯過去10年積累的海量翻譯資料正好提供了這樣一個學習的土壤。然後藉助TensorFlow開源機器學習平臺就可以進行大規模的訓練和自我學習,而爲了確保翻譯的速度,谷歌還專門為機器翻譯研發了一款名為TPU的硬體,比世界上現有正在使用的處理翻譯的軟硬體要快3倍。
目前這項翻譯技術已經支援包括英語、法語、德語、西班牙語、葡萄牙語、中文、日語、韓語、土耳其語這八組語言的互譯,谷歌接下來的目標就是進一步推廣到103種語言,覆蓋全球99%的人口。
本文來自騰訊科技




我們幫助您以高品質、高效率實現您的最終業務目標
 電子營業執照
電子營業執照
 蘇公網安備 32059002004138號
蘇公網安備 32059002004138號