 中國
中國 Global
Global

在傳統伺服器晶片市場,英特爾是個巨無霸,無論是IBM Power還是ARM陣營,所佔有的份額都微乎其微。但戰線轉移到人工智慧領域,IBM似乎更有優勢。
據外媒報道,近日IBM和NVIDIA聯手推出了新伺服器IBM Power Systems S822LC for High Performance Computing(還有兩款產品分別為IBM Power Systems S821LC和IBM Power Systems S822LC for Big Data),從這一串名字可看出,這並不是一款普通的伺服器,它是專門為人工智慧、機器學習和高階分析應用場景而推出的。
IBM官方宣稱,這款伺服器數數據處理速度比其它平臺快5倍,和英特爾x86伺服器相比,每美元的平均效能高出80%。
apper">
這款伺服器比英特爾x86強在哪?
據瞭解,該款伺服器使用了兩個IBM Power8 CPU和4個NVIDIA Tesla P100 GPU。Power8是目前IBM最強的CPU,從之前媒體的評測資料來看,其效能是要優於英特爾E7 v3的,而Tesla P100是NVIDIA今年才釋出的高效能運算(HPC)顯示卡,這樣的配置組合在處理效能上自然不弱。
原因有兩個:
其一,相比CISC指令集,採用的RISC指令集的Power處理器可同時執行多條指令,可將一條指令分割成多個程序或執行緒,交由多個處理器同時執行,因此並行處理效能要優於基於CISC架構的英特爾x86晶片。
另外,這款伺服器的巧妙之處還在於Power8和Tesla P100之間的「配合」。
Power架構的另一大特點就是具有充分發揮GPU效能的優勢。
實際上,Tesla P100有兩個版本,一個是NVIDIA今年4月推出的NVLink版,另一個是6月釋出的PCI-E版本,簡單來講,前者是後者的加強版,與IBM Power8配對的正是Tesla P100 NVLink版。
Tesla P100採用的是Pascal架構,能夠實現CPU與GPU之間的頁面遷移,不過每塊NVLink版還配置了4個每秒40 GB NVIDIA NVLink埠,分部接入GPU叢集。NVLink是OpenPOWER Foundation獨有的高速互連技術,其有效頻寬高達40GB/S,堪稱PCIE的升級版,足以滿足多晶片平行計算的需求。不過支援這一標準的CPU屈指可數,Power8則是其中之一(英特爾不在此之列)。
這就意味著,Power8 CPU能夠和Tesla P100 GPU以更高的速度完成通訊,這一特性可讓IBM Power Systems S822LC for High Performance Computing中的CPU和GPU之間的連線速度遠快於普通的在PCIe匯流排上交換資料的表現。
apper">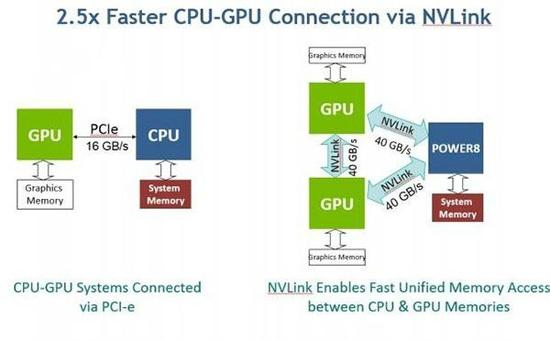
IBM表示,「這一功能意味著,不同於在GPU處於PCI-E介面上的x86系統上,資料庫應用程式、高效能分析應用程式和高效能運算應用程式執行能夠在要大得多的資料集上執行。」
另外,Tesla P100的半精度浮點運算效能達到了每秒21萬億次 —— 比插入現代PCI-E插槽的GPU高出大約14%,這樣的處理能力對訓練深度神經網路的重要性不言而喻。
IBM還做了個縱向對比,和老款Power S822LC伺服器的Tesla K80 GPU加速器相比,新款伺服器的加速能力提升了兩倍多。
預計明年問世的IBM Power9會延續對CPU+GPU組優化。
為何是「CPU+GPU」?
衆所周知,在人工智慧人工智慧和深度學習等計算任務上,CPU早已不堪重任。因此,不少企業紛紛推出人工智慧專用晶片概念,例如谷歌的TPU(Tensor Processing Unit);還有業內人士力挺FPGA更適合深度學習的演算法,這也是英特爾以高價收購Altera的主要原因。
不過,上述兩個替代CPU的方案都還未成熟,目前大多數企業採用的依然是「CPU+GPU」的組合,或者稱為異構伺服器。通常來說,在這種異構模式下,應用程式的序列部分在CPU上執行,而GPU作為協處理器,主要負責計算任務繁重的部分。
因為和CPU相比,GPU的優勢非常明顯:
當然,這並不代表人工智慧伺服器對CPU沒有需求,CPU依然是計算任務不可或缺的一部分,在深度學習演算法處理任務中還需要高效能的CPU來執行指令並且和GPU進行數據傳輸,同時發揮CPU的通用性和GPU的複雜任務處理能力,才能達到最好的效果,通俗點說就是實現CPU和GPU的協同計算。
雖然NVIDIA和Intel等晶片商正在為GPU和CPU孰強孰弱陷入了口水戰,但實際上這些企業已經開始在異構計算上加大了研發力度,至少在近期內,CPU和GPU的結合將繼續成為人工智慧領域最有效的方案。
本文來自新浪科技




我們幫助您以高品質、高效率實現您的最終業務目標
 電子營業執照
電子營業執照
 蘇公網安備 32059002004138號
蘇公網安備 32059002004138號